社内ヘルプデスクの運用を成功させるポイント

社内と社外ヘルプデスクの役割と範囲
ヘルプデスク運用の本質は、単なる「問い合わせ対応」ではありません。 業務の中断を最小限に抑え、 従業員の体験を向上させ、 最終的に事業全体の生産性と満足度を高める「攻めの運用基盤」を構築することにあります。
本記事では、まず社内向けと社外向けで異なる役割やKPI(重要業績評価指標)を整理します。その上で、ヘルプデスクを「対応の終着点」ではなく「改善の起点」として設計する前提をそろえましょう。

社内ヘルプデスクの目的と業務範囲
社内ヘルプデスクは、従業員の業務継続を支えるインフラです。PC・アカウント・SaaS・ネットワーク・周辺機器など横断領域の一次受けを担い、障害復旧や利用支援によって業務継続を実現します。
評価軸は、一次解決率や平均応答時間、SLA遵守率など、業務中断の短縮に直結する指標が中心です。
現場では、部署や拠点ごとに問い合わせ傾向が異なります。社内周知・ルール整備・資産台帳との連携まで含め、部門横断の情報共有が成功の鍵です。
社外ヘルプデスクの目的と業務範囲
社外ヘルプデスクは、顧客が製品・サービスを使いこなせる状態を継続させる接点です。トラブル解決はもちろん、導入支援や活用提案まで踏み込むことで、解約率の低減やアップセルにも寄与します。
評価軸は一次解決率やCSAT(満足度)、NPS、再発率など顧客体験の質を測る指標が中心です。
たとえばSaaSのヘルプデスクでは、営業・開発・品質管理と連携し、既知エラーの共有やUI改善へつなぐ循環を作るほど、同種問い合わせの再発を抑えられます。似た問い合わせを少しずつ減らすことで、サービス全体の使いやすさの評価向上に繋げられます。
コールセンターやカスタマーサポートとの違い
コールセンターは大量の入電を効率よく捌く受付処理の最適化が主眼で、KPIも応答率や平均処理時間など「量」の制御が中心です。一方でヘルプデスク運用は、技術的な原因分析、再現性のある手順化、ナレッジ化まで含めた「質」の向上が求められます。
カスタマーサポートとヘルプデスクは隣接領域ですが、サポートが使い方の案内に重点があるのに対し、ヘルプデスクは問題の特定と解決に重心があります。
理想は両者がFAQやナレッジを共有し、フロントでの案内とバックの原因除去が一つの循環で回る設計です。
| 観点 | 社内ヘルプデスク | 社外ヘルプデスク |
|---|---|---|
| 主要目的 | 業務中断の最小化・生産性向上 | 顧客体験の向上・継続率向上 |
| 主な範囲 | 端末・アカウント・SaaS・ネットワーク横断 | 製品/サービスの利用支援・障害対応 |
| 代表KPI | 一次解決率、SLA遵守率、平均応答時間 | CSAT/NPS、一次解決率、再発率 |
| 連携先 | 情シス、セキュリティ、各部門 | 営業、開発、品質管理、CS |
運用と保守の違いを理解する
ヘルプデスク運用では「運用」と「保守」という言葉が混同されがちですが、実務上は明確に切り分けねばなりません。この定義が曖昧だと、業務フローや責任範囲が不明確になり、対応漏れや非効率を招くためです。
ここでは両者の役割・業務プロセス・KPIの違いを整理し、効果的な分業設計のポイントを解説します。
業務プロセスの違いを整理する
「運用」とは、従業員やユーザーからの問い合わせに対応し、チケットを起票して処理を進めるなど、日々の業務を回す活動を指します。つまり「今起きていること」に反応して解決する反応型の仕事です。
一方で「保守」は、システムやツールが安定して動くようにする予防型の仕事です。
たとえば、ヘルプデスクのチケット管理システムを例に取ると、運用は「問い合わせを受け、チケットを登録・対応・クローズする」業務の流れそのもの。一方の保守は「システムを安定稼働させるためのバックアップ、アップデート、アクセス管理」など、土台を維持する領域です。
両者を切り分けた上で、SLA(サービスレベル合意書)を設計することが重要です。
体制の違いとKPIの着眼点
運用チームのKPIは「スピード」と「一次解決率」が中心です。問い合わせをいかに早く、かつ現場で解決できるかが成果を左右します。SLA遵守率や平均応答時間もよく使われる指標です。
一方、保守チームは「安定稼働」と「再発防止」がミッションです。稼働率、変更成功率、障害の再発防止率など、長期的な安定性を測る数値を追います。
運用がスピードと解決力を重視するのに対し、保守は持続性と安全性を重視すると考えると整理しやすいでしょう。
| 観点 | 運用 | 保守 |
|---|---|---|
| 目的 | 日常的な対応・サポートの継続 | システムや環境の健全性維持 |
| 性質 | 反応型(問い合わせ対応) | 予防型(障害防止・更新) |
| 主な業務 | チケット処理、エスカレーション、報告 | パッチ適用、バックアップ、設定変更 |
| 主要KPI | 一次解決率、平均応答時間、SLA遵守率 | 稼働率、変更成功率、再発防止率 |
役割分担と責任範囲の明確化
ヘルプデスク運用において重要なのは、「誰がどこまで対応するか」を明文化することです。
たとえば、ユーザー問い合わせの受付から一次対応までを運用チームが担い、システム設定変更や構成管理など技術的な修正を保守チームが担当するように定義します。これにより、曖昧な責任範囲による二重対応や抜け漏れを防止できます。
さらに、SLA(対ユーザー)とOLA(内部合意書)を紐づけることで、チーム間の役割分担がより明確になります。
ヘルプデスク運用の基本的な流れ
ヘルプデスク運用を安定させるには、「どんな順番で、どう処理するか」を明文化することが欠かせません。流れが決まっていないと、担当者ごとに対応方法がバラつき、抜け漏れが起きやすくなります。
ここでは、受付からクローズまでの一般的なプロセスを整理し、再現性のある運用にするためのポイントを解説します。
受付チャネルの設計と統合
まず重要なのは、問い合わせの「受付経路」を整備し、一元化することです。
電話・メール・Teams・Slack・チャットボットなど、複数チャネルで受け付けている場合でも、すべてをチケット管理システム上で集約し、対応漏れを防ぐ仕組みを構築します。
その中心となるのが SPOC(Single Point of Contact:単一窓口)設計 です。問い合わせ経路を統合し、チケット発行を自動化することで、誰が・いつ・何に対応しているのかが明確になります。
カテゴリと優先度、SLA・OLAの定義
ヘルプデスクの運用では、すべての問い合わせに同じ速度で対応するのは非効率です。 業務影響の大きさに応じて、適切に優先順位付け(トリアージ)を行うことが重要です。
優先度は一般的に「重要度 × 緊急度」で決定します。
たとえば、全社影響の障害は最優先(P1)、特定部署のみの設定トラブルは中優先(P2)、一部端末での軽微な不具合は低優先(P3)といった具合です。
さらに、それぞれに対応目標時間を設定し、達成率をモニタリングします。P1は「30分以内に初回応答・2時間以内に復旧見込み提示」といった形です。
SLA違反が発生した場合は、根本原因を分析し、プロセス改善やリソース再配分につなげます。社内の部門間で支援が発生する場合は、責任範囲や対応時間を明文化するとスムーズです。
エスカレーションと責任分界点の明確化
一次対応(L1)で解決できない案件は必ず発生します。 その際、「何を、いつ、誰(L2, L3)に引き継ぐか」を定めたエスカレーションルールが、対応の停滞や放置を防ぐ鍵となります。
たとえば、「1時間以内に一次対応で解決できなければ二次チームに引き継ぐ」「特定カテゴリの障害は専門チームが即時対応」といったルールを設け、チケット上で自動的に転送・通知される仕組みを作ります。
また、一次・二次・専門対応の責任分界点を明確に定義することが、業務の透明性を保ちます。曖昧な線引きは二重対応や放置の原因になるため、フロー図で明示し、教育時に共有しておくと効果的です。
クローズの条件と満足度の取得
対応が完了したら、単に「チケットを閉じる」だけで終わらせてはいけません。まずはユーザーに完了報告を行い、「解決を確認できたか」を明確にすることが重要です。これにより、解決チケットの再オープンを防げます。
その上で、満足度アンケートを実施し、定量・定性両面からフィードバックを収集します。特に「対応スピード」「説明のわかりやすさ」「再発有無」などの項目は、今後のナレッジ改善の材料となります。
得られたフィードバックは、ナレッジベースやFAQ更新、教育カリキュラムの改訂に反映することで、継続的な品質向上サイクルを実現できます。「どの説明が伝わりにくかったのか」「再発したケースはどんな傾向があるか」を見える化し、定例会議で共有しておくと、次の改善にすぐつなげられます。
体制設計と担当者の役割分担
ヘルプデスク運用を安定的に回すには、明確な体制設計が不可欠です。上述のとおり、「誰が・何を・どの範囲まで担当するのか」を定義しなければ、対応の抜け漏れや属人化が発生します。
ここでは、役割分担・シフト設計の観点から、最適な体制設計の考え方を整理します。
必要なスキルと育成の方向性
ヘルプデスク担当者には、ヒューマンスキルとテクニカルスキルの両立 が求められます。
問い合わせの多くは「わかりにくい説明」によって長期化する傾向があります。そのため、システムの知識やトラブル対応力はもちろん、相手の理解度に合わせて説明する力、共感をもって話を聞く姿勢も重要です。
特に社内ヘルプデスクでは、利用者のITリテラシーがバラバラなことが多いため、「わかりやすく伝える力」が成果を左右します。
また、ナレッジ共有の文化を育てることもポイントです。FAQやチケット履歴を教育素材として活用すれば、チーム全体でスキルを底上げできます。
シフト設計と繁忙期の対応
問い合わせ件数には「波」があります。月末・期初・新年度などに集中する傾向が強く、これを把握せずに固定シフトを組むと、担当者の負荷が偏ります。
ログ分析やチケットデータから、曜日・時間帯別の問い合わせ傾向を可視化し、ピークタイムに合わせてリソースを最適配置することが重要です。
特に、夜間や休日対応を求められる場合は、外部委託や自動化の活用 を検討します。チャットボットやFAQで一次対応をカバーし、緊急チケットのみオンコール担当に通知する仕組みを組み合わせると効果的です。
また、繁忙期には臨時スタッフや委託リソースを柔軟に投入できるよう、対応マニュアルや教育資料を標準化しておくことで、立ち上がりの早い補強体制を構築できます。人に依存しないシフト設計が、安定運用の第一歩です。
KPIと成果の可視化
ヘルプデスク運用の継続的な改善には、「感覚」ではなくデータに基づく判断が不可欠です。 KPI(重要業績評価指標)を体系的に設計し、成果(スピード・品質・効率)を可視化することが、課題の早期発見と改善サイクル定着の第一歩です。
ここでは、運用・品質・生産性の3つの指標設計を軸に解説します。
運用指標の設計
運用指標は、日々の対応スピードや安定性を測る基礎です。
代表的な指標には以下があります。
- 平均応答時間(FRT:First Response Time)
- ユーザーの初回問い合わせに対して、最初の返信が行われるまでの時間。
- ユーザーの初回問い合わせに対して、最初の返信が行われるまでの時間。
- 一次解決率(FCR:First Call Resolution)
- 一次対応で解決した件数の割合。再エスカレーションを防ぐ重要なKPIです。
- 一次対応で解決した件数の割合。再エスカレーションを防ぐ重要なKPIです。
- SLA遵守率
- 設定した対応目標時間内に処理できた割合。安定稼働の度合いを示します。
これらをダッシュボード上でリアルタイムに可視化すれば、遅延や偏りを早期に発見できます。
品質指標の設計
品質指標は、ユーザー体験やサービス満足度を測るものです。単に「対応件数が多い」だけではなく、「どれだけ満足度の高い解決を提供できたか」が重要です。
主な品質KPIには以下が挙げられます。
- 顧客満足度(CSAT)
- 対応完了後のアンケートで算出。
- 対応完了後のアンケートで算出。
- 再発率
- 同じ問題で再度問い合わせが発生した割合。
- 同じ問題で再度問い合わせが発生した割合。
- エスカレーション率
- 一次対応で解決できずに上位チームへ引き継いだ件数。
これらは定量指標に加えて、自由記述コメントなどの定性データも組み合わせると効果的です。「対応は早かったが説明がわかりにくい」などの声は、FAQ改善や教育内容の見直しに直接活用できます。
ユーザー体験を中心に置いた品質指標設計が、問い合わせ削減と満足度向上を同時に実現する鍵です。品質指標を単なる満足度調査で終わらせず、改善の入口として扱うことが大切です。
生産性指標の設計
生産性指標は、チームのリソースをどれだけ効率的に使えているかを測るものです。限られた人員の中で高い成果を出すには、どこに時間を使い、どれだけ削減できたかを数値で把握する必要があります。
代表的なものに以下があります。
- 処理件数/人・日
- 1人あたりの平均対応件数
- 1人あたりの平均対応件数
- 稼働率/稼働時間分布
- 担当者の工数配分を分析
- 担当者の工数配分を分析
- 自動化率/省力化効果
- 自動応答やテンプレート利用による削減効果
たとえば、チャットボットやスクリプトの導入によって月間対応件数が20%減少した場合、その削減時間を他の改善活動に回すなど、リソース最適化の意思決定に直結します。
生産性指標を継続的に追跡することで、投資効果(ROI)を可視化し、経営層への説得力ある報告が可能になります。
効率化と標準化のベストプラクティス
ヘルプデスク運用を長く続けていると、担当者ごとに対応方法が違ったり、似た問い合わせを何度も受けたりすることがあります。
こうした属人化やムダをなくすために大切なのが、「標準化」と「効率化」です。ここでは、FAQ整備やテンプレート化、自動化、継続的な改善といった実践的な方法を紹介します。
FAQとナレッジの整備
問い合わせの多くは、内容が繰り返される定型パターンです。このような質問を分析し、上位20件ほどをFAQ化することから始めると効果的です。FAQを単なるQ&A集にせず、カテゴリ設計と検索性を意識して構築することがポイントです。
たとえば、「システム設定」「アカウント管理」「エラー対応」などのカテゴリで分類し、キーワード検索やタグを設定すると、利用者が自己解決しやすくなります。
また、FAQは作って終わりではなく、更新責任者を明確にすることが重要です。これによりFAQの鮮度が保たれ、ナレッジの信頼性が維持されます。
テンプレートとスクリプトの活用
ヘルプデスクでは、似たような回答を繰り返し作成するケースが多く見られます。この対応を効率化するのが回答テンプレートです。
たとえば、「パスワードリセット」「システム障害のお知らせ」「利用権限の申請手順」など、よく使う文面を標準化することで、担当者の作業負荷を軽減できます。
さらに、定型業務をスクリプトやマクロで自動化することも有効です。たとえば、アカウントの初期設定や権限付与の処理を自動化すれば、対応時間を短縮し、ヒューマンエラーも防げます。
このような自動化は「教育・引継ぎ」の観点でも有効で、新人でも一定品質の対応ができるようになります。結果的に、属人化を抑え、運用の再現性が高まります。
ゼロ問い合わせを目指した仕組みづくり
効率化の最終形は「問い合わせを減らすこと」です。つまり、FAQやガイドの整備などによって、そもそも問い合わせが発生しない状態=ゼロ問い合わせを目指します。
そのためには、まず問い合わせデータを定期的に分析し、「なぜ発生したか」「どこでつまずいたか」を把握します。たとえば、「特定システムの操作ミス」が多ければ、UIやマニュアルの改善を開発部門と連携して進めます。
最近では、画面上で操作ガイドを表示する DAP(デジタルアダプションプラットフォーム) の導入も、ユーザー支援の新たな選択肢です。
このように、根本原因にアプローチする「源流対策」を継続することで、問い合わせ数を構造的に減らすことができます。
継続的な改善活動の仕組み化
標準化と効率化は、一度整えたら終わりではありません。環境やシステム、利用者の行動が変われば、ヘルプデスクの課題も変化します。そこで大事なのが、「改善を仕組みにして回すこと」です。
改善活動をイベントではなく文化として定着させることで、組織全体が学習する循環が生まれます。これが「強いヘルプデスク組織」への進化を支える鍵です。
成功事例と失敗事例から学ぶ
どの企業でも「改善の方向性は正しいのに、なぜか成果が出ない」というケースがあります。その違いは、仕組みの定着度と数値の使い方にあります。
ここでは、実際の現場で見られた成功・失敗パターンを紹介します。
成功事例:自己解決率を向上させたA社(製造業)
あるメーカー(A社)では、全国の社員から寄せられる社内IT問い合わせを限られたメンバーで対応していました。
特定の担当者に業務が集中し、担当不在時に対応が滞る「属人化」が課題でした。
そこで、過去8,000件の対応履歴をFAQ化し、問い合わせ状況と対応履歴をポータルで可視化したことで、誰でも同じ品質で対応できる体制を短期間で構築しました。
導入後は、問い合わせ数が月200件から120〜150件に減少。約8割の問い合わせがFAQまたは代行対応で解決できるようになり、対応進捗が可視化されたことで「放置されている不安」が解消され、社員満足度も向上しました。
FAQシステムによって、ナレッジの共有と業務負担軽減を両立した好例です。
失敗事例:ツール導入だけで終わったケース
一方で、ツールを入れただけで運用が形骸化してしまう失敗例も少なくありません。
チケット管理やFAQツールを導入したものの、目的やKPIが明確でなく、使い方も統一されていないと、ツールが「ただの問い合わせ記録」にとどまってしまいます。
こうした失敗を防ぐには、「導入目的」「改善サイクル」「更新責任者」を明文化しておくことが大切です。
ツールは仕組みの一部であり、運用設計と教育をセットで行うことが定着の鍵になります。
成功と失敗を分けるポイント
成功するヘルプデスクと失敗するヘルプデスクの違いを、以下の表にまとめます。
| 観点 | 成功する運用 | 失敗する運用 |
|---|---|---|
| 目的設定 | SLA・KPIが明確で、改善サイクルに連動 | 「問い合わせ対応」が目的化している |
| ツール活用 | チケット・FAQ・AIを連携運用 | ツールが孤立し、データが活かされない |
| ナレッジ管理 | 定期更新と効果測定を仕組み化 | 作って終わり、古い情報が放置 |
| 体制設計 | 役割・責任が明確で属人化しない | 判断が個人依存、引継ぎに弱い |
| 文化 | 改善が日常業務として根付いている | 改善は「特別対応」として後回し |
ツール導入とシステム設計
ヘルプデスク運用を支えるのは、人とプロセス、そしてそれを可視化・効率化するツール基盤です。
チケット管理・FAQ・チャットボット・社内ポータルなどを目的に応じて組み合わせることで、問い合わせ対応から改善までを一貫して管理できます。ここでは、主要ツールの活用ポイントと設計の考え方を整理します。
チケット管理システムの導入
チケット管理は、ヘルプデスク運用の中枢です。すべての問い合わせをチケットとして登録し、ステータス・担当・対応履歴を一元的に管理することで、対応漏れや重複対応を防止できます。
基本機能として重視すべきは以下の3点です。
- チケット番号による追跡性:進捗や履歴がすぐに確認できる。
- 自動ルーティング:カテゴリ・優先度・スキルに応じて担当者を自動割り当て。
- レポート機能:SLA遵守率や件数トレンドを自動可視化。
さらに、チケット履歴をナレッジベースと連携させることで、過去の解決事例を再利用できるようになります。これにより、担当者の経験に依存しない再現性の高い対応が実現します。
代表的なツールには、Jira Service ManagementやServiceNow などがあり、自社の規模や業務フローに合わせて選定します。
ナレッジとFAQシステムの活用
FAQシステムは、ヘルプデスクの自己解決率を高める最も効果的な手段です。単なる情報の蓄積ではなく、検索性・更新性・再利用性 の3要素を意識して設計することがポイントです。
たとえば、タグやカテゴリ設計を行い、ユーザーが自然な言葉で検索できるように工夫します。検索ログを分析すれば、「検索したが見つからなかった質問」や「重複するワード」を把握でき、FAQの改善に直結します。また、FAQを社内と社外で分け、権限管理を明確化することで、情報漏えいや混乱を防げます。
FAQの更新は、担当者が回答したチケット内容をナレッジ化するフローを定義しておくと、更新漏れを防ぎつつ自然にナレッジが蓄積します。
チャットボットや生成AIの活用
近年は、定型問い合わせを自動対応するチャットボットや生成AIの導入が進んでいます。特に、FAQと連携させたAIチャットは、24時間稼働できる一次対応窓口として有効です。
AIは問い合わせ内容を解析し、FAQデータベースから最適な回答を提示します。これにより、担当者は複雑な案件に集中でき、業務効率が大幅に向上します。
導入時のポイントは以下の通りです。
- 対象範囲の明確化:AIが対応できる質問領域を定義し、曖昧な応答を防ぐ。
- 回答品質の監視:誤回答や低評価のケースをログ分析して改善。
- 継続学習:新たな質問を逐次学習させ、回答精度を高める。
生成AIを活用する場合、FAQ・チケット履歴・社内マニュアルを統合した「ナレッジ基盤」を構築することが鍵です。AIはこの知識をもとに回答を生成し、人手では追いつかないスピードでナレッジを再利用できます。
社内ポータルと情報共有基盤の整備
最後に、社内ポータルや共有基盤の設計です。ヘルプデスク関連情報(FAQ、手順書、対応履歴、アナウンスなど)を一箇所に集約し、誰でも必要な情報に即アクセスできる環境を作ります。
Office365のSharePoint、Googleサイト、Notionなどを活用すると、簡易なナレッジポータルを低コストで構築できます。
設計の際は、以下の点を意識しましょう。
- 情報の集中管理:各部署やツールに散らばらない構造をつくる。
- アクセス権と更新履歴を明確にする:誰がいつ変更したかを追跡できるように。
- 検索・通知連携:TeamsやSlackと連携し、更新情報を自動通知。
共有基盤を整えることで、ナレッジが「担当者の頭の中」から「組織全体の資産」に変わります。新しいメンバーが加わってもスムーズに引き継ぐ環境が整い、チーム全体の対応力が底上げされます。
ヘルプデスク運用の立ち上げ手順
新しくヘルプデスクを立ち上げるときは、「まず何から手を付ければいいのか?」と悩む方も多いでしょう。
一気にすべてを整備しようとすると混乱しやすく、形だけの仕組みになりがちです。ポイントは、小さく始めて段階的に育てること。
ここでは、現状把握から試験運用、定着化までのステップを順に整理します。
ステップ1. 現状分析と課題整理
まず行うべきは、現状の問い合わせ実態の把握です。
問い合わせ件数、カテゴリ、発生時間帯、対応者の稼働状況などを定量的に分析し、現場の課題を明確にします。
あわせて、ヒアリングやアンケートを実施し、「なぜ問い合わせが多いのか」「どの手順で滞っているのか」といった定性情報も収集します。
たとえば、「同じ質問が何度も寄せられている」「特定システムでトラブルが集中している」などの傾向を把握すれば、優先順位をつけた改善計画を立てやすくなります。この段階で作成する課題マップは、運用設計の基礎資料として非常に有効です。
ステップ2. 最小構成での試験運用
次に行うのが、MVP(Minimum Viable Process)=最小構成での試験運用です。
いきなり全社展開するのではなく、特定部署やカテゴリに絞って小規模運用を行い、実データをもとに改善点を洗い出します。
この段階では、「問い合わせ受付」「チケット登録」「対応記録」「簡易レポート作成」までの基本機能を最小限で構築し、スピード重視で運用を回すことがポイントです。
フィードバックは週次で回収し、対応遅延、運用ルールの不明点などを即時修正します。小さく始めてすぐ改善することで、現場負荷を抑えつつ、完成度の高い運用フローを確立できます。
ステップ3. 教育と改善による定着化
試験運用で得た知見をもとに、正式導入へと移行します。
このフェーズでは、教育と改善をセットで行うことが定着のカギです。
教育面では、対応手順・ツール操作・エスカレーションルールをマニュアル化し、定期的な研修を実施します。新任担当者にはOJTと併せて、ロールプレイ形式で対応品質を標準化するのが効果的です。同時に、定例の改善会議を設け、KPIレビューやナレッジ更新を運用サイクルに組み込みます。
よくある課題とその解決策
ヘルプデスク運用の立ち上げや初期フェーズでは、同じようなつまずきが多く見られます。
ここでは、代表的な課題とその解決策を整理しておきましょう。
よくある課題① 問い合わせ件数の多さへの対策
立ち上げ直後は、問い合わせが集中しやすい時期です。この場合は、自己解決を促す仕組みを入れることが有効です。FAQの整備やチャットボットの導入で、簡単な質問を自動処理化しましょう。
また、問い合わせ内容を分析し、上位20件をFAQ化するだけでも効果があります。繰り返される質問を先回りで解消できれば、対応件数を20〜30%ほど削減できます。
よくある課題② 属人化を防ぐ標準化の進め方
「特定の人にしかわからない対応」が増えると、業務が止まりやすくなります。これを防ぐには、標準化と共有が必須です。
対応手順や判断ルールをチェックリスト化し、チケットテンプレートやFAQに反映させます。加えて、ローテーションや他メンバーの対応同行を定期的に行うと、チーム全体の知識が均一化します。
月1回のミニレビュー会で「対応の違い」を話し合うだけでも、属人化はかなり軽減されます。
よくある課題③ 説明がわかりにくく、再問い合わせが多い
説明が難しい、という課題の背景には、情報の伝え方があります。文章だけで伝えようとせず、画面共有や短い動画ガイド、スクリーンショット付き手順書などを組み合わせましょう。
また、「利用者のどのタイミングで迷うか」を分析すると、改善ポイントが明確になります。
再問い合わせが多い項目はFAQやガイドの順番を見直すことで、ユーザー体験が大きく向上します。
よくある課題④ 成果が見えにくく、評価されづらい
ヘルプデスクは裏方の役割が多く、成果が伝わりにくい部門です。この課題は、KPIと可視化で解決できます。
チケット件数の推移、一次解決率、SLA遵守率、FAQ閲覧数、満足度などをダッシュボードで共有しましょう。
数値だけでなく「改善事例」や「利用者の声」を加えると、チーム全体のモチベーションも上がります。
運用の価値を見える化することで、組織内の信頼が深まります。
外部委託と内製の比較
ヘルプデスク運用を継続していくと、多くの企業が「内製で続けるべきか」「外部委託(アウトソーシング)に切り替えるべきか」という選択に直面します。
どちらが正解ということではなく、業務の目的・コスト構造・社内リソース・スピード要求などによって最適解は異なります。ここでは、委託・内製それぞれの特徴を整理し、さらに運用を支える人の採用と育成まで含めて解説します。
外部委託の運用モデルと活用例
外部委託(BPO:Business Process Outsourcing)は、一次対応や夜間対応などを外部パートナーに任せ、社内は企画・改善・管理に集中するモデルです。
特に以下のようなケースでは効果を発揮します。
- 問い合わせ件数が多く、対応が追いつかない
- 24時間・多言語対応など社内でカバーしきれない要件がある
- 社内リソースをコア業務(企画・改善・戦略)に集中させたい
たとえば、平日日中は社内チーム、夜間や休日は外部パートナーが一次対応を行うハイブリッド運用が一般的です。これにより、コストを抑えながらも24時間体制を実現できます。
外部委託で失敗する典型例が、委託範囲のあいまいさです。「どこまでを委託し、何をKPIとして評価するか」をSLA(サービスレベル合意書)で厳密に定義しなければ、必ず品質の低下や連携ミスを招きます。 TS(ReSM)が金融機関の運用で培った知見からも、SLAとKPIに基づく厳格な定例レビューの実施は、アウトソーシング成功の絶対条件です。
ベンダー選定の評価基準
委託先を選ぶ際は、単に価格や知名度だけで判断してはいけません。特に重視すべき評価軸は以下の通りです。
| 評価項目 | チェックポイント |
|---|---|
| SLA・KPI設計力 | 応答時間・解決率などを数値で管理できるか |
| 教育・ナレッジ体制 | 担当者教育・FAQ整備・品質チェックの仕組みがあるか |
| セキュリティ・情報管理 | 個人情報・社内データを安全に扱う体制が整っているか |
| 改善提案力 | 定例レポートや改善提案を積極的に行っているか |
| 実績・専門性 | 同業界・同規模でのサポート実績があるか |
また、委託後も定期的なKPIレビューを行い、成果に応じて契約内容を見直すのが理想です。任せっぱなしではなく、共に改善するパートナーとして関係を育てる視点を持ちましょう。
委託費用と見積もりの考え方
委託費用は「件数単価型」「時間単価型」「成果連動型」など複数の契約形態があります。自社の運用目的に合わせて、適切な契約を選ぶことが重要です。
| 契約形態 | 特徴 | 向いているケース |
|---|---|---|
| 件数単価型 | 問い合わせ1件ごとに課金 | 件数が安定している場合 |
| 時間単価型 | 稼働時間で課金 | 波がある業務や臨時対応が多い場合 |
| 成果連動型 | KPI達成度に応じて報酬が変動 | 品質・満足度重視の運用に最適 |
見積もり時は、件数・時間だけでなく、教育コスト・管理コスト・改善工数を含めた総コストで比較検討します。
また、契約更新時にはKPIを見直し、成果に基づいて契約条件を再設定することで、継続的な費用対効果の最適化が図れます。
人材採用と育成のポイント
外部委託か内製かを問わず、ヘルプデスク運用の品質は人の力に左右されます。
ここからは、採用・教育・キャリア形成の3つの観点で、運用を支える人材設計のポイントを整理します。
求められる人物像とスキルセット
ヘルプデスク担当者に必要なのは、IT知識だけではありません。問い合わせ対応には、「聞く力」と「伝える力」の両方が求められます。
| スキルカテゴリ | 具体的な内容 |
|---|---|
| ヒューマンスキル | 傾聴力、説明力、共感力、冷静な判断 |
| テクニカルスキル | OS・ネットワーク基礎、SaaS設定、セキュリティ知識 |
| 改善スキル | ログ分析、傾向把握、ナレッジ共有 |
| チームスキル | 他部門との連携、引き継ぎ、教育 |
採用段階では「成長意欲」と「誠実さ」を重視するのがおすすめです。知識は後から身につけられますが、コミュニケーション姿勢は一朝一夕では変えにくい部分です。
採用後の教育と継続学習
採用後は、体系的な教育設計が鍵になります。まずはチケット対応やSLA理解など基本的な業務を覚え、OJTで実践的にスキルを積み上げていきます。
▪️教育のステップ例
- 基礎研修(対応ルール・マナー・ツール操作)
- OJT(先輩とペアで実務対応)
- フォローアップ研修(月次の振り返り)
- ナレッジ共有会(成功・失敗事例の共有)
キャリアパスへの考え方
ヘルプデスク職はキャリアが頭打ちになりやすいと思われがちですが、実際は幅広い成長ルートがあります。
一次対応からスタートし、二次対応・運用設計・品質管理・マネジメントへと段階的にステップアップできます。
| ステージ | 主な役割 | 評価の軸 |
|---|---|---|
| 初級(一次対応) | 基本対応、記録、報告 | 応答スピード・正確性 |
| 中級(二次対応) | トラブル分析、改善提案 | 一次解決率・再発防止率 |
| 上級(リーダー) | 教育、改善、ナレッジ管理 | チームKPI・教育成果 |
| 管理職(マネージャー) | SLA設計、ベンダー管理、戦略設計 | 全体KPI・満足度 |
キャリアステップを明確に設計することで、担当者のモチベーション維持と定着率の向上につながります。「運用を設計できる人」が評価される時代だからこそ、学びをキャリアとして見せる仕組みが大切です。
運用ガバナンスとセキュリティ管理
ヘルプデスクは日々の業務で、社員情報やアカウント情報、システム設定など、企業の重要データに直接触れるポジションです。そのため、効率的な運用と同じくらい重要なのが、セキュリティとガバナンスを両立した仕組みづくりです。ReSMが支援するお客様でもこの両立は非常に重要視されています。
ここでは、情報保護・変更管理・インシデント対応を中心に、安全で持続可能な運用体制の構築方法を解説します。
データ管理とアクセス制御
まず基本となるのは、最小権限原則の徹底です。担当者が必要な範囲以上のシステム権限を持つと、誤操作や情報漏えいのリスクが高まります。
具体的には以下のような制御を設けます:
- 権限分離:一次対応者は閲覧のみ、管理者のみが変更・削除権限を持つ
- 認証強化:多要素認証(MFA)やアクセス元制限を設定
- アクセスログの記録:操作履歴を自動保存し、定期的に監査
さらに、退職・異動時にはアクセス権を自動停止する仕組みを導入します。これにより、人的ミスによる不正アクセスを未然に防止できます。
チケット管理システムやFAQツールなど複数のプラットフォームを利用している場合は、SSO(シングルサインオン)を活用し、アカウント統制を一元管理するのが理想です。
変更管理とインシデント対応体制
ヘルプデスク運用では、「設定変更」や「システム修正」といった日常作業の中に潜むリスクを管理する必要があります。これを体系化するのが、変更管理プロセスです。変更のたびに、以下の手順を標準化しておくと安全性が格段に高まります。
- 変更申請:担当者が申請書を提出(目的・影響範囲・リスクを明記)
- 承認:管理者または上長が内容を確認し承認
- 検証:テスト環境で動作確認を実施
- 実施:本番環境で変更を実行
- 報告とレビュー:結果をチケットに記録し、再発防止策を共有
この手順を徹底すれば、「うっかり設定を変えてシステム障害が発生した」といったヒューマンエラーを防げます。
また、インシデント発生時は、即時対応・原因分析・再発防止をワンセットで実行することが重要です。
ガバナンス強化のためのルールと教育
ルールを整備しても、それを現場で守らなければ意味がありません。そのためには、ガバナンスを「仕組み」と「文化」の両面で浸透させることが必要です。
仕組み面では、定期監査や内部統制チェックリストを設け、実運用とルールの乖離を早期に発見します。
文化面では、セキュリティ意識を高めるために、定期的な教育・訓練を実施します。
たとえば、年1回のセキュリティ研修に加えて、四半期ごとの「想定インシデント訓練」や「フィッシング模擬演習」を行うと効果的です。また、教育成果をKPIとして可視化する(例:教育受講率、理解度テスト結果など)ことで、形式的な研修に終わらせず、実効性を担保できます。
まとめ
ヘルプデスク運用の本質は、「問い合わせを早く処理すること(反応型)」ではなく、「問い合わせを減らす仕組み(予防型)」と「再現性のある高品質な対応体制(標準化)」を構築することです。
社内ヘルプデスクは「業務を止めない支援」、社外ヘルプデスクは「顧客体験を高めるサポート」として、それぞれ明確な目的とKPIに基づき運用設計することが、事業の生産性向上に直結します。
社内ヘルプデスクの本当の問題は、対応件数ではなく「問い合わせが減らない構造」にある
PCトラブル、アカウント管理、ツールの使い方…。
一件ずつは軽微な作業でも、積み重なることで情シスの稼働を圧迫し、改善や企画に手をつけられない状態を生んでいます。
FAQを整備しても、問い合わせが減らないのは、「人が答える前提」の運用から抜け出せていないからです。
「また同じ質問か…」
「プロジェクトに割く時間がない」
そんな状況が、毎日繰り返されていませんか。
生成AI x 有人対応で、問い合わせそのものを減らす
AI社内ヘルプデスク「ReSM plus(リズムプラス)」
ReSM plusは、生成AIと有人オペレーターを組み合わせた社内ヘルプデスクサービスです。
単なる問い合わせ代行ではなく、「問い合わせを減らす仕組み」を企業の中に定着させることを目的としています。
- よくある問い合わせは生成AIが即時に回答
- AIで解決できない内容は、ReSM plus社員が回答
- 有人対応の内容はナレッジ化し、生成AIに追加
- アカウント発行・パスワード初期化など、問い合わせ発生源の巻き取りも可能
AIだけでも、人手だけでもない。
両者を組み合わせることで、現場に無理のない形でヘルプデスクを進化させます。
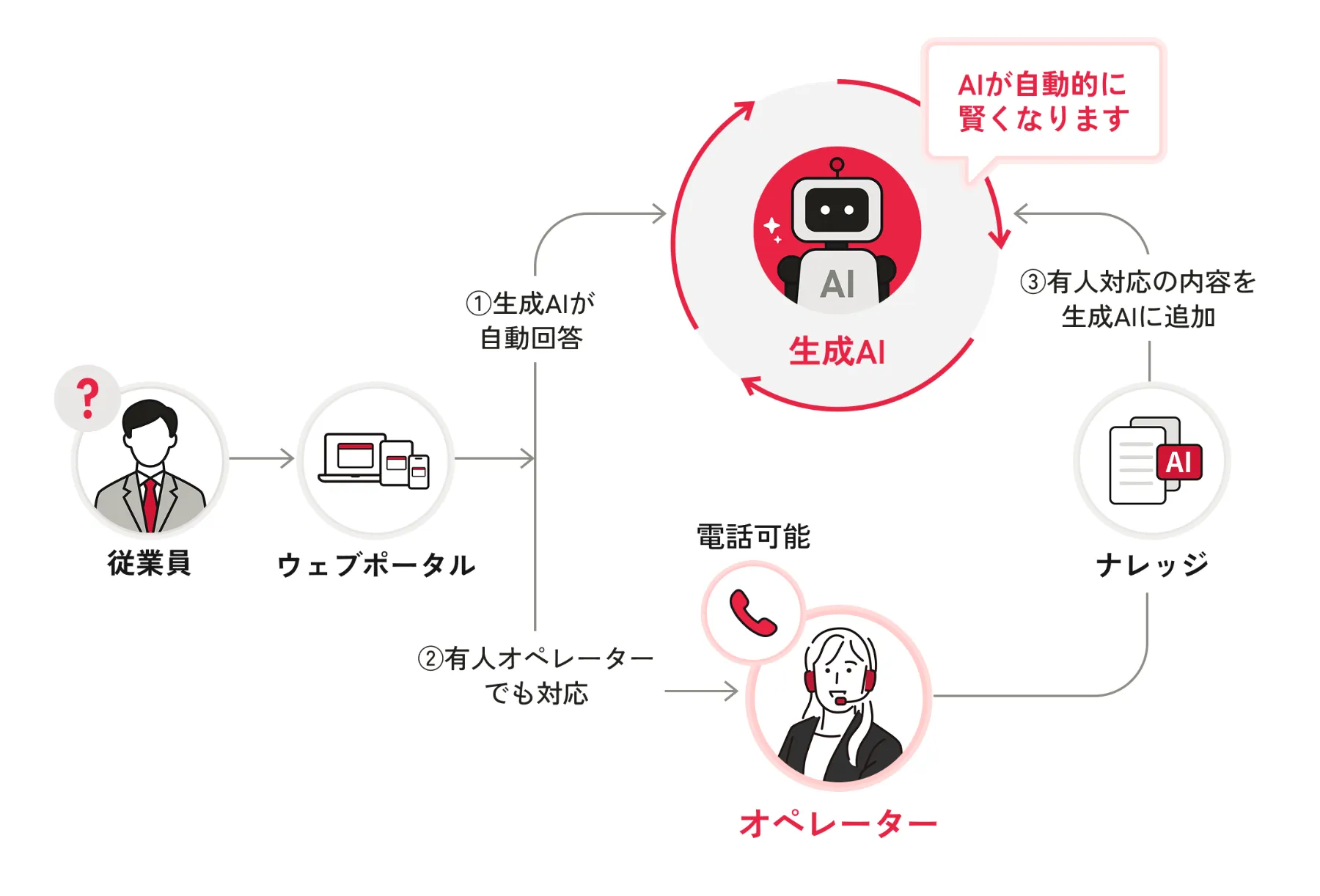
生成AIが社内問い合わせに自動回答
生成AIが社内ドキュメントやFAQを参照し、問い合わせに即時回答します。従業員は専用ポータルから質問するだけで、迷わず回答にたどり着けます。
その結果、現場は待ち時間が減り、情シスは対応件数そのものが減少。問い合わせ対応に追われない、余裕のある体制を作ることができます。
専門オペレーターによる有人対応
生成AIで対応が難しい問い合わせや、あえてAIに任せたくない内容は、ReSM plus社員が貴社に代わって対応します。
ITやPCに強い専任オペレーターが継続して対応するため、対応品質が安定し、引き継ぎや説明の手間も最小限に抑えられます。
使うほど、問い合わせ対応が減っていく
有人対応した問い合わせはFAQとして整理・ナレッジ化され、生成AIに反映されていきます。
そのため、問い合わせが増えるほどAIがより正確に答えられるようになり、同じ質問はAIで完結します。
AIと有人対応が連動し、ReSM plusのAI社内ヘルプデスクは使うほどに進化していく仕組みです。
パスワード初期化やアカウント作成といった問い合わせの発生源ごと巻き取る
PCセットアップやアカウント発行、IT資産管理…
こうした問い合わせを生む原因そのものを巻き取ることで、対応件数を根本から減らす設計が可能です。業務フローの一部をReSM plusに預けることで、情シスの予防的な働き方を支援します。
FAQやナレッジが十分に揃っていなくても、心配はいりません。
今ある社内資料を活かしながら、FAQの新規作成や、有人オペレーターが対応するためのマニュアル整備まで、ReSM plusが一括で支援します。
「準備に時間が取れない」
「何から手を付けるべきか分からない」
そんな情シスでも、無理なく導入できます。
この記事の著者






関連するサービス


お問い合わせ
依頼内容に迷っているときは、課題の整理からお手伝いします。
まずはお悩みをご相談ください。
-

システム運用監視・保守サービスReSM(リズム)ご紹介資料
クラウドの導入から24時間365日のシステム運用監視まで、ITシステムのインフラをトータルでサポートするReSM(リズム)サービスについて詳しく説明します。
-

4つのポイントで学ぶ「失敗しないベンダー選び」
運用アウトソーシングを成功させる第一歩は、サービスベンダーの選択です。この資料ではサービスベンダーを選択するポイントを4つ紹介します。