トレンドとなっているSRE(Site Reliability Engineering)とは?従来のDevOpsと何が違う?

従来、システムを開発する役割と運用する役割は「システムの価値を高める」という共通の目標を持っているにもかかわらず、深い溝が生まれる傾向がありました。この問題を解決する考え方としてDevOpsが生まれましたが、このDevOpsを具現化する取り組みであるSREが最近注目されています。
Googleが提唱したSRE(Site Reliability Engineering)とは?
SRE(Site Reliability Engineering)とは、Googleが提唱するシステム運用の方法論です。旧来の運用業務は、手順書に沿ってアプリケーションをリリースする、サーバーメンテナンスを行う、ハードウェア障害に対して復旧作業を行うといった、いわばミドル層以下の領域における手作業の業務が中心でした。そのためアプリケーションを開発するエンジニアと運用のエンジニアは役割・チームが完全に分かれているのが一般的でした。
しかしアプリケーション開発は開発したら終わりではなく、開発したものをリリースした後に、安定的に運用されなければなりません。にもかかわらず旧来は役割が開発以降の工程で分断されていたため、ひずみが発生していました。
開発担当者にとっては開発したものをどんどんリリースすることで利用者の利便性が向上するため、システムの価値(利便性向上)を高めると考えますが、運用担当者にとってはリリースする数が多ければ多いほど、問題が発生する確率が高くなり、システムの価値が下がると考えます。
本来は利便性向上も安定した稼働もシステムの価値向上には欠かせないものです。そこでGoogleではシステムの価値を総合的に考えて価値向上のために活動するグローバルなSREチームを形成しました。
SREでは開発者と運用者の垣根を超えてより安定的な運用管理を行っていく
たとえば発生した問題はアプリケーションのプログラムミスが原因かもしれないし、リリースの手順ミスかもしれません。アプリケーションのパフォーマンスが低下している場合は、ハードウェアのリソースの他にもプログラムのコーディングが原因となることもあります。そのため複雑な障害の調査では、プログラミングの知識も必要とされます。
そこでSREのチームには従来の運用業務だけでなく、コーディングの改善を提案するといった業務も含まれており、開発エンジニアに近い仕事をこなします。
一方で開発チームの方でも運用エンジニアに近い仕事をこなします。なぜかというと安定稼働していない時には、開発よりも安定稼働のための改善を優先しなければならないからです。
安定稼働しているかの判断でカギとなるのが、SLO(Service Level Objective:サービスレベル目標)の設定です。「レイテンシ」「スループット」「リクエスト率」「可用性」といったシステムが安定的に稼働しているかを測る明確な数値を定めます。
この時に重要となる要素が「エラーバジェット」です。例えば可用性を99.95%と設定すると、止まってもよい時間の割合が0.05%となります。停止時間がそれを下回る(エラーバジェットが残っている)のであれば、開発チームは新たなリリースをどんどんやってよいということになります。逆に停止時間が設定よりも上回る(エラーバジェットが残っていない)なら、開発を停止して安定稼働のための運用業務に人的リソースを割り当てなければなりません。このエラーの割合を予算として考え、予算があるなら開発ができるという考え方です。
このように稼働状況によって開発と運用の割合を増やしたり減らしたりするというのが、従来になかった考え方です。そしてこれを実現するには開発者と運用者が一体になって進める必要があります。
SREとDevOpsの違いとは?
SREの考え方は開発 (Development) と運用 (Operations) を組み合わせた「DevOps」と同じではないかと思われる方もいるかもしれません。両者の違いについてGoogleでは“class SRE implements DevOps”というメッセージを発信しています。これはオブジェクト指向プログラミングになぞらえた表現なのですが、DevOpsで定義されている抽象的な概念をSREで具体的な取り組みとして実践するという意味合いになります。
つまりDevOpsそのものは厳密な定義がなく、抽象的な概念でしかありません。DevOpsは以下の領域を扱います。
●組織のサイロを削減する
●エラーが発生するのを前提とする
●段階的に変更する
●ツールと自動化を活用する
●すべてを計測する
これに対してSREとしてどのように取り組むかについては、Googleがノウハウを公開しています。日本語のドキュメントは購入する必要がありますが、英語のドキュメントは無料で公開されています。(https://landing.google.com/sre/)
SREのポイントとなるのは、オペレーションの自動化
安定稼働を実現するにはミスの起こりにくい環境にしなければなりません。そのためには自動化が必須です。自動化を実現するには、システム構成を変更するのに必要なハードウェアの操作についてもソフトウェア上でできるようにプログラムで実装することが求められます。
今まではアプリケーションの実行環境を構築するといった業務ひとつひとつに複雑な手順が必要でしたが、インフラ構成をプログラミングコード化・自動化することで、ミスなく迅速な環境構築が可能になります。
GoogleのSREチームでは、定型作業の多い運用業務を50%以下に抑え、残りを自動化のように生産性の高い活動に割り当てることをルールとしています。今まで泥臭い仕事とされてきた運用業務を再定義し、創造的な仕事として位置づけています。
SREを実践するための方法とは?ベンダーとの協業も
SREは国内に企業にも広がりを見せており、Web系サービス事業者を中心に取り入れられています。ものづくりの世界でもソフトウェアで付加価値をつける取り組みが当たり前の時代になっていることから、SREを実践しているメーカーも存在します。SREの取り組みが経営に確かなインパクトを与えるという考え方は、今後ますます浸透していくでしょう。
とはいえ、実際に自社にどのように適用していけばいいのかという部分については、まだハードルが高いと言わざるを得ません。開発と運用の分断に問題があるという認識はあるものの、人的リソースや予算が限定的で、自動化に取り組む時間が取れない、開発チームと運用チームの意識を変えることが難しい、そもそも自動化に拒否反応がある等、SREを取り入れるにはリソースや体制、文化の問題が立ちはだかります。
こうした問題を解決するためには、ノウハウを持つベンダーと協業する方法もあります。自社の形態にあったSREのデザインや体制づくりなど、外部のノウハウ・リソースを活用しながら、効率よく進めていくことができます。
縁の下の力持ちの存在だった運用業務に光を当て、クリエイティブな仕事に導くSREの取り組みが、今後さらに広がっていくのか注目です。
止めないシステム運用のはずが、現場は疲弊していませんか?
システムを安定稼働させるには、24時間365日の監視体制が必要。それは分かっていても、実際に回し続けるのは簡単ではありません。
夜間や休日に障害が起きたとき、誰が対応するのか曖昧なまま。アラート対応も日々のルーチンもすべて人に依存し、疲弊だけが蓄積していく。
しかも、改善しようと思っても、手が空かない。目の前の対応に追われて、運用ルールの見直しや仕組み化が後回しになる。結果として、「この体制で本当に守り切れるのか?」という不安だけが残るのです。
24時間365日の運用監視サービス「ReSM リズム」
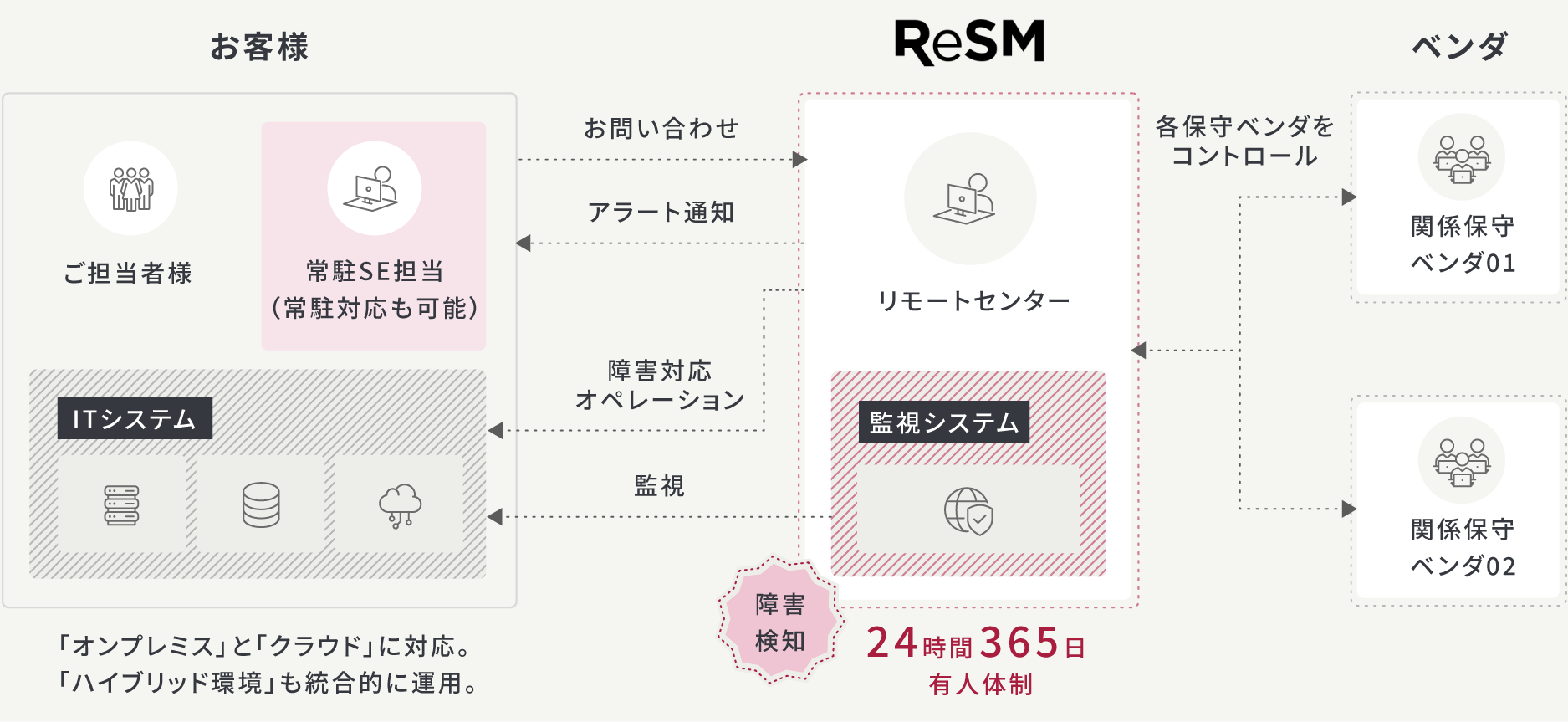
ReSMでは、常駐型、リモートセンター、常駐とリモートのハイブリッドなど、お客さまの課題と予算に応じて柔軟な運用体制を構築します。専任の常駐担当者による高度運用からコストを最適化した支援まで、高い品質と納得の価格を両立。障害対応からベンダーのコントロールまで、ITシステム運用に必要なサポートをまとめて提供します。
数ある運用監視サービスの中でも、ReSMが選ばれる理由は大きく分けて以下の3つです
- 大企業採用のシステム運用を最適なコストで提供
- 安心・セキュアなリモートセンター
- システム設計構築から運用保守までワンストップ支援
大企業採用のシステム運用を最適なコストで提供
総合SIerとして50年以上の歴史をもつ株式会社DTSが運営しています。金融や通信をはじめとしたエンタープライズ運用のノウハウを結集し、品質と信頼性をそのままに、より多くの企業にご利用いただけるサービスを目指しています。
安心・セキュアなリモートセンター
震度6以上の地震や長時間停電に耐えうる設計のデータセンター建物で運営しています。センター建物入り口に24時間常駐の警備員を配置し、非接触型ICカード式セキュリティ管理システムによるエリア(部屋)単位での多段認証を採用。監視カメラによる不正侵入監視、ログ蓄積も実施し、安心の体制でサービスを提供します。
システム設計構築から運用保守までワンストップ支援
エンタープライズシステムの設計構築に携わるPMクラスの技術者が多数在籍し、業務システムからウェブシステムまで、さまざまなシステムの設計構築と運用保守が可能です。また、大手SIerやAP開発ベンダーとのパートナーシップで、より付加価値と費用対効果の高いITサービスを提供しています。
ReSMのシステム監視・運用を導入し、システムを止めない仕組みを外部化し、本来取り組むべき企画・改善業務へリソースを再配分しませんか。

この記事の著者







関連するサービス



お問い合わせ
依頼内容に迷っているときは、課題の整理からお手伝いします。
まずはお悩みをご相談ください。
-

システム運用監視・保守サービスReSM(リズム)ご紹介資料
クラウドの導入から24時間365日のシステム運用監視まで、ITシステムのインフラをトータルでサポートするReSM(リズム)サービスについて詳しく説明します。
-

4つのポイントで学ぶ「失敗しないベンダー選び」
運用アウトソーシングを成功させる第一歩は、サービスベンダーの選択です。この資料ではサービスベンダーを選択するポイントを4つ紹介します。