ITILにおけるインシデント管理と問題管理の違いは何ですか?

インシデント管理の全体像とITILでの位置づけ
ITサービスを運用する中で避けられないのが、システム障害や不具合といったインシデントです。
これらを適切に管理できなければ、業務停止や顧客満足度の低下を招き、事業継続に大きな影響を与えます。利用者が業務を止めずに済むよう、発生した事象へ最短で対処し、通常サービスへ戻すことがインシデント管理の目的です。
単なる障害対応の現場テクニックとして消費せず、ITILの標準プロセスに沿って役割・手順・KPIを整備し、組織のレジリエンスを高める仕組みとして位置付けられます。
以降では、概念の境界とビジネス影響を押さえたうえで、実務に転用しやすい型としてポイントを整理します。
インシデントの定義と境界
インシデント管理を理解する第一歩は、「インシデントとは何か」を正しく押さえることです。
インシデントとは、ITサービスの通常利用を妨げるあらゆる事象を指します。サーバ障害やネットワーク切断のようなシステム完全停止だけでなく、アプリケーションの動作遅延や誤動作、ユーザーがログインできないといった不具合も含まれます。
一方で、労災などの物理的事故は別系統として扱い、サイバー攻撃の兆候は情報セキュリティ・インシデントとして連携しながら管理します。
ここで重要なのは「業務に支障が生じているかどうか」であり、必ずしも大規模な障害だけを対象とするわけではありません。
一方で「事故」や「ヒヤリハット」との混同も起きやすく、定義が曖昧だと初動判断が遅れ、対応品質が下がる原因となります。
そこで、グレーケースを一次的に受け入れてから再分類する運用や、用語集と判断基準をテンプレート化する取り決めを用意します。
ビジネスへの影響と重要性
インシデント対応のスピードと正確さは、ビジネス継続性と顧客満足度を大きく左右します。
システム停止によるダウンタイムが1時間でも発生すれば、ECサイトでは数百万円単位の売上損失につながることがあります。社内業務システムが止まれば、受発注や給与計算などの基幹業務が滞り、組織全体の信頼性が揺らぎかねません。
こうした背景から、多くの企業ではインシデント管理を単なる障害対応にとどめず、経営課題の一環として捉えています。レジリエンス強化、すなわち「迅速に立ち直る力」を養うことは、サイバー攻撃や災害の脅威が増す現代において不可欠です。
適切なインシデント管理体制を整えることは、顧客や社員からの信頼を維持し、事業の安定成長を支える基盤となります。
ITILにおける位置づけ
国際的なITサービスマネジメントのベストプラクティスであるITILでは、インシデント管理はサービス運用の中核的なプラクティスとして位置づけられています。
その目的は「障害の根本原因を解決すること」ではなく、「いち早く通常のサービスを復旧させること」にあります。つまり、恒久対策は後続の問題管理に委ね、インシデント管理は利用者が業務を継続できる状態を最優先に追求するのです。
また、ITILはプロセスを標準化し、組織内外で共通の言語として活用できる点が強みです。
インシデント管理をITILの枠組みに沿って実装することで、属人性を排除し、再現性の高い対応を実現できます。さらに、KPIとして平均復旧時間(MTTR)や初回解決率を設定し、継続的改善に結びつけることが推奨されています。

インシデント管理と問題管理の違い
インシデント管理と問題管理は混同されやすいものの、目的・成果物・時間軸が異なります。両者を切り分けることができれば、現場の対応はよりスムーズになり、改善サイクルも効率的に回ります。
ここでは、それぞれの役割と指標を整理したうえで、実務上の連携方法を解説します。
目的と成果物とKPIの比較
インシデント管理と問題管理はしばしば混同されがちですが、その目的と成果物は明確に異なります。
インシデント管理の目的は「通常業務をいち早く復旧させること」であり、成果物は復旧手順や対応記録です。評価指標としては平均復旧時間(MTTR)、初回解決率、SLA遵守率などが使われ、スピードと安定性が重視されます。
一方、問題管理の目的は「根本原因を突き止め、恒久的に解消すること」にあります。成果物は原因分析レポートや恒久対策の実装計画であり、KPIは再発率の低下や恒久対策の実行率が中心となります。
時間軸で見ると、インシデント管理は短期的対応、問題管理は中長期的改善に位置づけられます。
両者を混同すると、復旧が遅れたり、恒久対策が後回しになるなど、改善サイクル全体に悪影響を及ぼすため注意が必要です。
実務での連携とエスカレーション
実際の運用現場では、インシデント管理と問題管理は分断して考えるのではなく、密接に連携させることが重要です。たとえば、暫定対応で復旧したインシデントは、そのまま放置せず問題管理に引き継ぎ、恒久対策へとつなげる必要があります。
ここで活用されるのが「既知エラーDB(Known Error Database/record)」であり、過去の原因分析や回避策を蓄積することで、再発時の迅速な対応を可能にします。
エスカレーションルールも連携の要です。
復旧が難しい場合には、迅速に問題管理チームや上位サポートに引き渡す仕組みを持つことで、対応の遅れや責任の曖昧さを防げます。特に重大インシデント(P1)では、経営層への報告ラインまで含めた明確なエスカレーションが、組織の信頼維持に直結します。
以下の表に、インシデント管理と問題管理の違いを整理しました。
| 項目 | インシデント管理 | 問題管理 |
|---|---|---|
| 目的 | サービスの迅速な復旧 | 根本原因の特定と恒久的解決 |
| 成果物 | 復旧手順、対応記録、SLAレポート | 原因分析、恒久対策計画、既知エラーDB |
| KPI | MTTR、初回解決率、SLA遵守率 | 再発率低下、恒久対策実行率 |
| 時間軸 | 即時対応・短期的 | 長期的・継続的 |
| 主な役割 | インシデントマネージャ、一次サポート | 問題マネージャ、二次・三次サポート |
標準フローの全体像:検知から振り返りまで
インシデント管理のフローは、検知から振り返りまでを一連の流れとして捉えることが肝要です。役割や報告ラインを明確化し、コミュニケーションを標準化することで、迅速かつ信頼性の高い対応が実現します。
役割と責任と報告ライン
インシデント管理を成功させるには、あらかじめ役割と責任を明確に定義することが不可欠です。
現場では「誰が初動を取るのか」「誰に報告するのか」が曖昧だと、対応が二重化したり、逆に誰も動かないという事態が起こりがちです。
ITILではインシデントマネージャが全体統括を担い、一次対応チームが初動を行い、必要に応じて二次・三次サポートへ引き渡す流れを推奨しています。さらに重大インシデントでは、経営層や広報部門などへのエスカレーションが欠かせません。
報告ラインを標準化しておけば、責任の所在が明確になり、初動の遅れを防げます。
ステークホルダーコミュニケーションの型
重大インシデント時に利用者や顧客への報告が遅れたり不十分だと、不信感や混乱を招きます。そのため「誰に・いつ・どのような内容を伝えるか」を標準化することが重要です。
たとえば、初報では発生を迅速に伝え、復旧見込みが立てば経過報告を行い、復旧完了後には正式なクローズ報告を出す、といった流れです。
利害関係者ごとに伝える内容を調整することも欠かせません。経営層には事業影響や顧客対応方針を、現場担当には具体的な手順や代替策を伝えるといった具合です。
適切な情報共有は、組織全体に安心感を与え、信頼維持につながります。
フロー全体の俯瞰
インシデント管理は「検知→分類→優先度決定→初動対応→復旧→クローズ→振り返り」という一連の流れで構成されます。このプロセスを部分最適で捉えると、属人性や抜け漏れが発生しやすくなります。
全体を可視化したフロー図を共有し、誰もが同じ理解で動けるようにすることが重要です。
特に、検知と初動対応に偏ってしまい、振り返りが形骸化するケースが多く見られますが、改善サイクルを回すためには「振り返り」こそ欠かせない工程です。
フロー標準化の意義
標準化されたフローは、対応の再現性を高め、属人性を排除する効果を持ちます。新任担当者でも手順に従えば一定の品質で対応できるようになり、担当者依存から脱却できます。
また、プロセスが可視化されていることで、どの工程に課題があるのかを分析しやすくなり、継続的改善の基盤になります。さらに、外部監査や顧客からの要求にも応えやすくなるため、組織全体のガバナンス強化にも寄与します。
ステップ1 検知と通報と記録を統一
検知と通報、そして記録の統一は、インシデント管理における「入口の品質」を担保する最重要ポイントです。
標準化された受付窓口と起票ルールを整えることで、初動を確実にし、後続プロセスの精度とスピードを大きく向上させることができます。
監視とアラートと受付窓口の集約
インシデント管理の第一歩は、異常をいかに早く、正確に検知できるかにかかっています。近年はシステム監視ツールによる自動アラートと、ユーザーからの申告が並行して存在するケースが多く見られます。
しかし、検知経路が分散していると、同じ事象が二重起票されたり、逆に誰も把握していないインシデントが生じるリスクがあります。これを防ぐためには、監視アラートとユーザー通報を一元的に受け付ける窓口を明確化することが重要です。
サポートデスクや専用ポータルを一本化された入口とすることで、初動の混乱を避け、対応スピードを高められます。
起票の必須項目
通報を受けた際には、記録を残すことが次工程の基盤となります。
記録が曖昧だと、復旧対応や後の分析が滞る原因となるため、起票時に必ず記録すべき必須項目を定義しておく必要があります。代表的な項目としては、発生時刻、影響範囲、影響を受けたサービス名、暫定回避策の有無、通報者情報などが挙げられます。
これらをテンプレート化し、誰が記録しても同じ水準の情報が残るよう標準化することで、情報の欠落や品質のばらつきを防げます。
記録の質が後工程を左右する
実務では、通報内容が「動かない」「遅い」といった抽象的な表現で終わっていることが少なくありません。その場合、原因分析や影響範囲特定に余計な工数がかかり、対応全体のスピードが低下してしまいます。
記録の質を高めるためには、入力支援(プルダウン選択や自動入力補助)やレビュー体制を整えることが有効です。
特に、後で分析に活用するための粒度を意識した記録が求められます。質の高い記録は、再発防止やナレッジ資産化にも直結するのです。
▪️起票例
| 項目 | 入力例 | 入力形式 | 目的 |
|---|---|---|---|
| 発生日時 | 2025-09-30 10:42 | 自動/日時 | 影響期間の特定 |
| 影響サービス | EC-Checkout | 選択 | 通知先と優先度の基礎 |
| 影響範囲 | 顧客全体/部門/個人 | 選択 | 重大度判定 |
| 症状 | 応答>10s/500増加 | 選択+自由記述 | 再現と切り分け |
| 暫定回避の有無 | 有/無 | 選択 | 復旧方針の判断 |
| 添付 | ログ/スクショ | ファイル | 証跡確保 |
| 連絡先 | 担当・内線/チャットID | 自由 | 連絡経路の明確化 |
一元化による効果
検知・通報・記録を統一することで、インシデント対応全体に好循環が生まれます。情報の見逃しや重複対応を防げるだけでなく、過去のインシデントと突き合わせて迅速に対応できる可能性が高まります。
さらに、集約された記録は分析や改善活動の基礎データとなり、将来的な自動化やAI活用にもつながります。
ステップ2 分類と影響範囲の特定
インシデントの分類と影響範囲特定は、対応プロセスの「心臓部」ともいえる工程です。
サービス停止やセキュリティ事象といった代表的な分類を標準化し、CMDBやサービスマップを連携させることで、迅速かつ正確に影響範囲を把握できます。
代表的なタイプ別の例示
インシデントを正しく分類することは、優先度判断や影響範囲特定の出発点です。分類が曖昧だと対応のばらつきや遅延につながり、利用者に不公平感を与えることもあります。
代表的な分類例としては「サービス停止」「性能劣化」「セキュリティ関連事象」「ユーザー操作ミス」「外部要因(災害・停電など)」が挙げられます。これらの区分を明確にルール化し、事例とセットで提示することで、担当者の判断迷いを減らすことが可能です。
また、グレーゾーンのケースについても「原則はこの区分に含める」といった補足ルールを用意しておくと、実務上の混乱を避けられます。
CMDBとサービスマップの活用
分類と同時に、影響範囲を迅速に特定することが求められます。ここで活用できるのが構成管理データベース(CMDB)やサービスマップです。
これらはシステム構成要素やサービス間の依存関係を可視化しており、「このサーバが止まるとどのサービスに影響が及ぶか」を即座に把握できます。
たとえば、データベース障害が発生した際に、影響を受ける業務システムやユーザー部門を素早く特定できれば、関係者への通知や復旧作業の優先順位付けがスムーズになります。
CMDBとインシデント管理ツールを連携させれば、起票時に自動で影響範囲を提示する仕組みも構築可能です。
分類精度が復旧速度を決める
実務の現場では「とりあえず起票」されたインシデントが後から整理されることも少なくありません。しかし、分類が曖昧なまま進めると、誤った優先度設定や誤対応につながり、復旧全体のスピードを落とす原因となります。
そこで、一次受付の段階で一定レベルの分類精度を担保することが重要です。
担当者教育やチェックリスト整備に加え、自動分類支援機能を持つツールを活用すれば、人によるばらつきを減らせます。
ステップ3 優先度付けの基準を設計
優先度設計は、インシデント管理の「意思決定の軸」となる部分です。ビジネス影響・法規制・ユーザー体験を考慮した基準を設け、優先度ごとに報告や更新頻度を整合させることで、現場の混乱を防げます。
ビジネス影響と法規制とユーザー影響
インシデントの優先度を決める際には、単に「技術的な深刻度」だけでは不十分です。ビジネスへの影響、法規制違反のリスク、ユーザー体験の低下といった観点を組み合わせて判断する必要があります。
たとえば、社内システムの一部不具合であっても、給与計算の遅延につながれば従業員満足度に直結しますし、ECサイトの停止は即売上損失となります。また、金融や医療の分野では、システム障害が法令遵守違反や安全リスクに直結するため、重大度が自動的に高く設定されます。
ユーザーから見た利便性や安心感も加味した総合的な視点が求められます。
優先度と更新頻度の整合
優先度を設定した後は、それに応じた報告や情報更新の間隔を標準化することが重要です。
重大インシデント(P1)の場合は、数分〜数十分単位で進捗報告を行い、関係者の不安を軽減します。
一方で、中程度以下のインシデントは1日数回の更新で十分な場合もあります。更新頻度が過少だと「放置されている」と誤解され、逆に過剰だと現場の負担を増やします。
優先度ごとに更新ルールを定めることで、情報の過不足を防ぎ、安心感と効率性を両立できます。
優先度付けの一貫性
優先度はケースごとに判断されるため、人によって基準が異なると混乱が生じます。
たとえば、ある担当者は「システム停止=常に最優先」と判断し、別の担当者は「影響ユーザー数」で判断する、といったバラつきが現場で頻発します。
優先度は「影響度(Impact)× 緊急度(Urgency)」で決めます。影響度は「どれだけ広く深く業務に影響するか」、緊急度は「どれだけ早く対応すべきか」です。判断基準をマトリクスで固定し、誰が見ても同じ結論になるようにします。
| 優先度 | 重大度(影響範囲) | 緊急度 | 典型例 |
|---|---|---|---|
| P1 | 全社的、顧客多数に影響 | 高 | ECサイト全面停止、基幹システム停止 |
| P2 | 部門単位で業務支障 | 中 | 部門システム障害、特定サービス停止 |
| P3 | 個別ユーザーに限定 | 低 | 個人端末の不具合、軽微なエラー |
このような基準を文書化し、訓練やレビューを通じて定着させることで、優先度付けの一貫性が担保されます。
参考までに影響度の考え方ですが、実務で迷わないよう、最初は2軸だけで十分です。
- 範囲(誰が影響を受けるか)
全社・顧客多数 / 複数部門 / 単一部門 / 限定ユーザー - 深さ(どれだけ止まるか)
全面停止 / 重要機能停止 / 性能劣化・断続 / 代替策あり
ステップ4 初動対応とエスカレーションを高速化
初動対応は、インシデント対応全体のスピードを決める最重要工程です。ランブックやプレイブックを整備して標準化し、チャットツールでの即時共有を徹底することで、迅速かつ正確な対応が実現します。
さらに、エスカレーションルートを事前に設計しておくことで、責任の曖昧さを排除し、組織全体での早期復旧につなげられます。
ランブックとプレイブックの整備
インシデント対応において、初動の質が復旧速度を大きく左右します。現場の判断に依存して属人的に動くと、対応が遅れたり、誤った手順を踏むリスクが高まります。
そこで有効なのが、あらかじめ定型化された手順をまとめた「ランブック」や、特定シナリオごとの対応フローを整理した「プレイブック」です。
たとえば「メールサーバ停止時の切り替え手順」や「セキュリティインシデント検知時の初動連絡フロー」などを事前に用意しておくことで、誰が担当しても一定品質の対応が可能になります。さらに、ツールと連携して一部手順を自動化すれば、初動を一層迅速化できます。
チャット運用と連絡経路の標準化
初動対応では、関係者間の情報共有スピードも極めて重要です。
メールや電話だけに頼ると、伝達の遅れや連絡漏れが発生しやすいため、リアルタイム性の高いチャットツールの活用が有効です。
SlackやMicrosoft Teamsを利用して専用チャンネルを立ち上げ、発生直後から状況を共有することで、意思決定が加速します。さらに「誰にメンションするか」「情報更新の書式をどうするか」といったルールを標準化しておくと、混乱を防ぎ、効率的な情報伝達が可能になります。
初動対応の属人性排除
現場では「ベテラン担当者が来ないと動けない」といった属人化が課題となりがちです。属人性を排除するためには、トリアージ基準を明確に定め、一次対応者が迅速に判断できる環境を整えることが必要です。
また、技術的なエスカレーション(例:二次サポートへの引き渡し)と管理的なエスカレーション(例:経営層や顧客への報告)を切り分け、両方のルートを標準化しておくことが効果的です。
これにより「誰が・どこまで対応すべきか」が明確になり、初動の混乱を避けられます。
ステップ5 復旧とクローズの基準を明文化
復旧とクローズの基準を明確にすることは、インシデント管理の品質を維持するうえで欠かせません。暫定対応と恒久対策を切り分け、記録と通知を徹底し、復旧完了の定義を事前に共有することで、責任の曖昧さを排除できます。
暫定回避と恒久対策の切り分け
インシデント対応では「とにかく早く業務を復旧させる」ことが第一目的ですが、その場しのぎの対応に終始してしまうと、同じ障害が再発するリスクが残ります。そこで重要なのが、暫定回避策と恒久対策の切り分けです。
たとえば、システム障害時に代替サーバへ切り替えて業務を再開するのは暫定対応にあたり、その後の根本原因を突き止めてパッチを適用するのが恒久対応となります。
復旧と同時に「この対応は暫定か恒久か」を明文化することで、問題管理への引き渡しがスムーズになり、クローズの曖昧さを防げます。
クローズ時の記録と通知
復旧が完了したら、正式にクローズするための基準と手順を定めておくことが必要です。
クローズの際には「発生日時・影響範囲・暫定対応・恒久対策予定・復旧完了時刻」といった情報を漏れなく記録し、関係者へ通知します。特に顧客向けサービスであれば、復旧報告を速やかに行うことで安心感を与えられます。
また、記録は単なる報告にとどまらず、今後の改善活動に活用できるナレッジ資産となります。これを体系的に蓄積することで、再発時の迅速な対応や教育にも役立ちます。
▪️復旧チェックリストの例
| 項目 | 内容 | 完了判定 |
|---|---|---|
| 復旧確認(技術) | メトリクス正常、アラート消失 | Yes/No |
| 復旧確認(業務) | 代表ユーザーで業務確認 | Yes/No |
| 暫定/恒久の区別 | 対応の性質を明記 | Yes/No |
| 影響総括 | 影響範囲/時間/件数 | Yes/No |
| 通知 | 関係者/顧客/ステータスページ | Yes/No |
| 連携 | 問題管理への起票/リンク | Yes/No |
復旧完了の定義
現場では「どの時点を復旧完了とみなすか」が曖昧になりがちです。
サービスが動作するようになった瞬間を復旧とするのか、利用者確認まで完了して初めて復旧とするのか、基準を明文化しておかなければトラブルが長引く恐れがあります。復旧定義を事前に合意形成しておくことで、関係者間の認識ずれをなくし、クローズ判断を迅速化できます。
ステップ6 振り返りで学習を積み上げる
振り返りは、インシデント管理を単なる「対処」から「学習と改善」へと進化させるプロセスです。ポストモーテムを体系的に実施し、KPIを継続的に更新することで、再発防止と成熟度向上を実現できます。
ポストモーテムの進め方
インシデントが収束した後に行う「ポストモーテム(事後検証)」は、単なる反省会ではなく、再発防止と改善につなげるための重要な学習プロセスです。
進め方としては、まず事実を正確に整理し、発生から復旧までの経緯をタイムライン化します。次に、原因と要因を特定し、暫定対応と恒久対策の妥当性を検証します。
そのうえで、学んだ教訓を抽出し、具体的な改善項目を責任者と期限付きで定義することが望まれます。
特に「誰が悪かったか」を追及する場にしてしまうと、担当者が萎縮し、正確な情報共有が妨げられるため注意が必要です。ポストモーテムは責任追及ではなく「学習の場」と位置づけることが、継続的改善の文化を育む鍵となります。
指標の更新と運用改善
振り返りの過程では、KPIやSLO(Service Level Objective)と照らし合わせて成果を評価します。代表的な指標には平均復旧時間(MTTR)、初回解決率、重大インシデント発生件数、再発率などがあります。
これらの数値を定期的に見直し、改善状況を可視化することで、組織全体が進化している実感を持てます。
さらに、ダッシュボードでリアルタイムに共有すれば、現場担当者から経営層まで一貫した認識を持てるため、改善活動が組織に定着します。指標改善を単なる数値管理に終わらせず、日常のオペレーションに落とし込むことが重要です。
振り返り文化の定着
多くの組織では、インシデント後に振り返りを行わず、そのまま日常業務に戻ってしまう傾向があります。これでは同じ失敗を繰り返すリスクが高まり、組織の成熟度が上がりません。
振り返りを定常化するためには、定例会議のアジェンダに組み込む、改善項目をガバナンス体制で追跡する、といった工夫が必要です。
振り返りの文化が根付けば、現場担当者も「改善の一員」として主体的に参画し、組織全体の対応力が強化されます。
海外フレームの要点を押さえる
SANSの六つのステップ
インシデント管理の国際的なベストプラクティスとして、SANS(SysAdmin, Audit, Network, and Security Institute)が提唱する「六つのステップ」が広く参照されています。
このフレームワークは、①準備(Preparation)、②識別・特定(Identification)、③封じ込め(Containment)、④排除(Eradication)、⑤復旧(Recovery)、⑥学習の共有(Lessons Learned)の6段階で構成されます。
特に「①準備」と「⑥学習の共有」を強化すると、対応スピードと再発防止の両方が進みます。演習で手順を見直し、学びをルールに反映する——このサイクルが現場力を底上げします。
NISTのガイド
米国国立標準技術研究所(NIST)が策定した「コンピュータセキュリティインシデントハンドリングガイド」では、「インシデント対応をリスク管理の流れに組み込む」ことを重視します。
それは、①準備、②検知、③対応、④復旧、⑤学習 をぐるっと回すイメージです。
中小〜中規模の組織であれば、まずは最小限の型から始めるのが現実的です。
・検知と通報の窓口を一本化する
・優先度(影響×緊急度)とエスカレーションの基準を決める
・復旧の定義とクローズ手順を明文化する
・振り返りで学びを残す
この4点を運用に乗せたうえで、自社の業務や規制要件に合わせて広げていくのが安全です。
このフレームワークの特徴は、構造が簡潔で運用に組み込みやすい点にあります。たとえば、中小規模の企業では複雑な手順を整備するのが難しいことも多いため、NISTのモデルを参考に最小限の枠組みを導入し、自社に合わせてカスタマイズするのが現実的です。
海外フレームを導入する意義
SANSやNISTといった国際的なフレームワークは、いずれも体系化され成熟度が高いのが特徴です。これらをそのままコピーするのではなく、自社の業務プロセスや組織文化に合わせて取り入れることで、運用品質を底上げできます。
海外標準を参照することで「自社はどの段階に位置しているか」を客観的に把握でき、外部監査や顧客からの信頼を高めることにもつながります。グローバルにビジネスを展開する企業にとっては、世界標準の視点を持つことが競争力強化の一環ともなります。
よくある課題と失敗パターン
形式的な起票と記録不足
インシデント管理における典型的な失敗の一つが、形式的に起票はされているものの、内容が不十分なケースです。
「システムが落ちた」「遅い」といった抽象的な記録では、後続の分析や改善活動に活かせません。結果として、同様の障害が発生した際に過去の事例を参照できず、毎回ゼロから対応することになります。
これを防ぐには、必須項目を明確にしたテンプレートの導入や、記録内容のレビュー体制を整えることが重要です。入力補助機能を持つツールを活用すれば、記録の質を標準化しやすくなります。
P1偏重とバックログ滞留
重大インシデント(P1)にばかり注力し、中程度以下のインシデント(P2・P3)が後回しになってしまうのもよくある課題です。
表面上は「大きな火消し」はできても、バックログとして蓄積した小規模インシデントが放置され、ユーザーの不満や潜在的なリスクを拡大させてしまいます。
特にP2やP3の中には、放置すれば後に重大障害へと発展するものも含まれています。優先度設定に基づいて計画的に処理し、バックログ管理を徹底することが、全体的なリスク低減には不可欠です。
属人化と初動遅延
もう一つの失敗パターンは、特定の担当者に依存した属人化です。経験豊富なスタッフがいないと初動が遅れる、あるいは誤った判断を下す、といった事態が頻発します。
属人化は短期的には便利に見えても、長期的には組織の脆弱性となります。ランブックやプレイブックを整備し、誰でも一定品質で初動対応できるようにしておくことが肝要です。
ツールとシステムの選び方と比較の観点
Excel管理の限界と移行の判断
多くの企業では、インシデント管理をExcelやスプレッドシートで始めるケースが少なくありません。
導入コストが低く、初期段階では十分機能するからです。しかし、件数が増えたり対応内容が複雑化すると、Excel管理にはすぐに限界が訪れます。
属人化による記録の不統一、集計や検索の手間、権限管理の不備などが顕著な課題です。この段階に達したら、専用システムへの移行を検討するべきです。
特にインシデント件数が月100件を超える、複数部門での横断的な対応が必要、といった状況では、早期の移行が業務効率を大きく改善します。
ツールのタイプと主な機能
インシデント管理ツールには大きく分けて、問い合わせ管理型、プロジェクト管理型、ITサービスマネジメント(ITSM)型があります。
問い合わせ管理型はユーザー窓口を強化するのに適しており、チケット起票や進捗管理が中心機能です。プロジェクト管理型はタスク管理やガントチャートといった要素を取り込み、複数チームでの連携をサポートします。
ITSM型はITIL準拠のプロセスを包括的にカバーし、CMDBやSLA管理など高度な機能を備えている点が特徴です。
自社の運用規模や成熟度に応じて、どのタイプが最適かを見極める必要があります。
必須機能と拡張機能の線引き
ツール導入時には「最初から全機能を求めない」ことが成功のポイントです。必須機能としては、起票・チケット管理、SLA遵守のための通知機能、進捗や復旧時間のレポート機能が挙げられます。
一方、AIによる自動分類や予測分析、チャットOps連携などは拡張機能として位置づけ、運用が成熟してから段階的に導入するのが望ましいアプローチです。必須と拡張を明確に区分することで、無駄な投資を避けながら、柔軟に成長できる基盤を整えられます。
連携の重要ポイント
どれほど高機能なツールでも、既存のシステムと連携できなければ運用が分断されてしまいます。
特に監視システム、CMDB、チャットツール(TeamsやSlack)との統合は欠かせません。また、ID管理やセキュリティ基盤と連携してログインを統制することで、ガバナンス面でも強化が図れます。
導入前には必ず「自社で既に運用しているシステムとの親和性」を評価し、連携性を重視して比較検討する必要があります。
比較チェックリスト
ツール選定を進める際には、以下の観点で比較することが効果的です。
- 操作性(現場が直感的に使えるか)
- 拡張性(将来の機能追加に対応できるか)
- コスト(初期導入費用とランニングコスト)
- 可用性(クラウド・オンプレの選択肢や冗長性)
- セキュリティ(権限管理やログ監査の仕組み)
これらを定量的に評価し、組織に最も適したツールを選ぶことが、長期的な運用安定につながります。
運用立ち上げと成熟化のロードマップ
インシデント管理は「最小実装から始め、演習と改善を重ねて成熟化させる」ステップ型のアプローチが適しています。小さく始めることで負担を抑えつつ、訓練とガバナンスを通じて組織全体に改善文化を浸透させることが可能です。
このロードマップを意識すれば、短期的な立ち上げと長期的な成熟度向上の両立を実現できます。
最小実装のチェックリスト
インシデント管理の運用は、一度に完璧を目指すよりも「小さく始めて改善する」アプローチが効果的です。最初の立ち上げ段階では、以下の最低限の要素を整備することが重要です。
- 受付窓口の統一(通報経路を一本化)
- 優先度付け基準の明文化
- 標準化された通知テンプレート
- 振り返りの仕組み(ポストモーテム実施)
これらを導入すれば、属人性を抑えつつ基本的なインシデント対応サイクルを確立できます。初期段階では「必要最低限を確実に回す」ことが成功の鍵です。
訓練と模擬障害の運用
立ち上げた運用を形骸化させないためには、定期的な訓練や模擬障害の実施が欠かせません。いわゆる「ゲームデー」と呼ばれる演習では、意図的にシステム障害を発生させ、現場がどのように対応するかを検証します。実際の現場でしか見えない課題が洗い出され、改善につながります。
また、演習を繰り返すことで、現場担当者の対応力や部門間の連携力が自然と強化されます。訓練を定常化することは、インシデント管理を「文化」として定着させる第一歩です。
改善ガバナンスと合意形成
運用を成熟させるには、改善活動を継続させる仕組みを組織のガバナンスに組み込む必要があります。具体的には、定例レビューでインシデント対応の結果や改善項目を確認し、責任者と期限を明確にすることが有効です。
また、改善内容を全員に共有し、現場担当者も合意形成に関与させることで「改善は一部の人の仕事」ではなく「全員で取り組む活動」として根付かせられます。
このプロセスが定着すれば、組織全体の成熟度は段階的に高まり、継続的な改善サイクルが回るようになります。
まとめ
インシデント管理は、単なる障害対応の枠を超え、組織の事業継続性と信頼性を支える中核プロセスです。
定義やITILでの位置づけを正しく理解し、問題管理との違いを明確にすることから始めることで、対応の迷いを減らし、復旧と恒久対策の両立が可能になります。
インシデント管理の成熟とは「小さく始め、継続的に改善し、組織全体で文化として根付かせること」に他なりません。その積み重ねが、ダウンタイム削減や顧客信頼の維持につながり、企業の持続的な競争力を支える基盤となります。
IT運用が「仕組み」ではなく「個人の工夫」に頼り切っていませんか?
問い合わせ対応やトラブル対応は、なんとか現場でこなせている。でも、その一つひとつが属人的で、記録にも残らず、再発防止にもつながらない。対応フローがないまま各自の判断で進み、引き継ぎも曖昧、情報も散在していく。こうした状態では、どれだけツールを導入しても、改善は一向に進みません。なぜなら、ITサービス運用に本当に必要なのは、「仕組みの設計」だからです。
DTSのITSM導入支援サービスは、Jira Service Managementを用いて、バラバラな対応ルールや情報の分断を解消し、IT運用をプロセスと責任で回る“仕組み”に変える支援を行います。
IT運用を整備し、対応品質を標準化する「ITSM導入支援サービス」
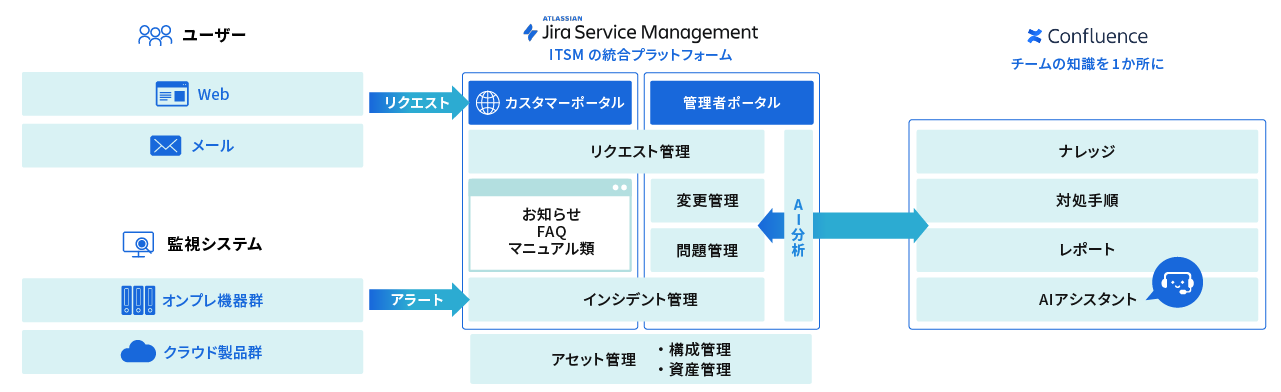
DTSのITSM導入支援サービスは、Jira Service Managementを活用し、バラバラな対応ルールや情報の分断を解消し、IT運用をプロセスと責任で回る“仕組み”に変える支援を行います。
単なるツールの導入ではなく、現場の業務にフィットするプロセス・ルール・役割設計を支援することで、判断の基準化・対応の再現性・組織的なナレッジ活用を実現します。
数ある運用改善サービスの中でも、DTSのITSM導入支援が選ばれる理由は、以下の3つです。
- 分散された問い合わせ窓口の一元管理化
- そもそもの問い合わせを削減
- AIと自動化で応答スピードと精度を強化
それぞれの特徴についてご紹介していきます。
分散された問い合わせ窓口の一元管理化
DTSでは、Jira Service Managementを活用し、すべての問い合わせを1つのポータルに集約。 カテゴリ別のフォームで自動分類・チケット発行し、対応の可視化とステータス管理を実現します。
加えて、対応者・対応履歴・進捗状況をリアルタイムで共有できるため、 属人化・対応漏れ・情報のブラックボックス化を防止し、“見えるIT運用”へと変革します。
そもそもの問い合わせを削減
「また同じ質問がきた」「担当者が変わると引き継げない」こうした問い合わせは、対応するほど増えていく構造的な問題です。
ReSMでは、問い合わせ傾向を分析し、ナレッジベースやFAQを整備。再発しやすい問い合わせには自己解決できる導線をあらかじめ用意し、問い合わせ件数そのものを減らす仕組みを設計します。
AIと自動化で応答スピードと精度を強化
チケット対応に人手がかかりすぎる、初動のレスポンスが遅い―― そんな課題には、AIチャットやワークフロー自動化の活用が効果的です。
DTSでは、Jira Service Management上でAIによる問い合わせ分類や自動返信・自動アサインなどの設計を支援。 現場の負担を減らしながら、スピードと正確性の両立した対応体制を実現します。
この記事の著者
近い課題のコラムを見る







関連するサービス



お問い合わせ
依頼内容に迷っているときは、課題の整理からお手伝いします。
まずはお悩みをご相談ください。
-

システム運用監視・保守サービスReSM(リズム)ご紹介資料
クラウドの導入から24時間365日のシステム運用監視まで、ITシステムのインフラをトータルでサポートするReSM(リズム)サービスについて詳しく説明します。
-

4つのポイントで学ぶ「失敗しないベンダー選び」
運用アウトソーシングを成功させる第一歩は、サービスベンダーの選択です。この資料ではサービスベンダーを選択するポイントを4つ紹介します。